As you may know, there aren’t only Western character encoded websites on the web. There are also websites in Chinese, Japanese, Arabic, etc., and we wanted to know how XLT would perform if we use it for testing a non-Latin website. Non-Latin does not necessarily mean non-UTF-8, but in this case it especially means non-Western characters and right-to-left (RTL). Or in other words, things a normal European or American programmer is not used to.
So, for the first time we tested a non-Latin website, precisely an Arabic one. We created a test case with the Script Developer to test an Arabic news website. The test entered Arabic words in a search field and validated the response to check the correctness of the website’s content. Afterwards, we ran the script as a JUnit Test in Eclipse. It was successful. The test was short, but provisionally it proved that XLT also works for non-Latin websites.
Furthermore, we ran the same test in a real browser and it worked as well. We used the FirefoxDriver to simulate user-like actions in Firefox to see if the WebDriver also works with non-Latin input.
When we continued testing, we observed some facts that may interest people who don’t often use Arabic as an input language. As you might know, Arabic is written from right to left. We noticed that there’s a difference between what appears and what actually happens technically. The following example illustrates that.
Placement of the Asterisk
We inserted a text assertion command in the test case. It was an ends-with validation, i.e. the asterisk should be at the first position if the input language is Latin. So, theoretically, if the input language is Arabic, then the asterisk should be at the first position of the Arabic text (the far right), but that wasn’t the case. The asterisk was at the first position from the Latin point of view (the far left).
Then, we tried inserting the asterisk at the first position of the Arabic text (the far right), but as you can see in the figure below the evaluation failed because the asterisk’s encoding is Latin-1, and accordingly the first position is then the far left according to the computer. So, we tried to insert the asterisk in Arabic (as input language), but the evaluation failed, as well.

The next picture shows how it should be.
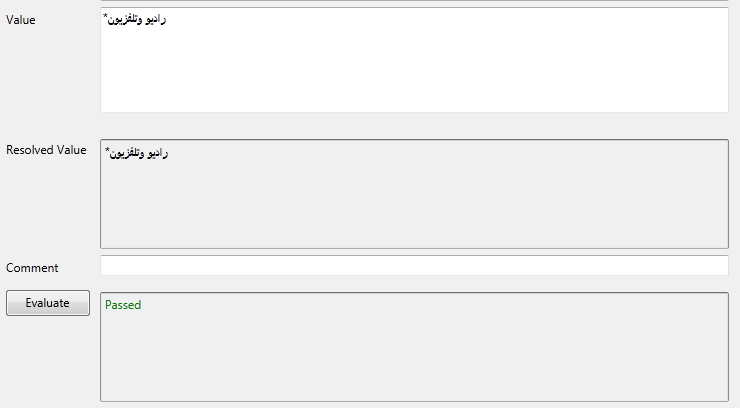
It was really hard trying to switch our way of thinking to the “right way”. We spent so much time trying to figure out how to insert the asterisks in the test cases and trying to understand the Arabic point of view.
Not all Asterisks are the same
So, in this case the asterisk must be inserted in Latin. Firstly, the asterisk will be inserted at the last position of the Arabic text and secondly, it has another code. As it turns out, the Arabic asterisk does not have the same code as the Latin asterisk. The Latin asterisk’s code in Unicode code points is U+002A and the Arabic one’s is U+066D, and it even has another name. It is called “Arabic Five Pointed Star” and it actually looks differently. You might be wondering why that is. We asked ourselves the same thing, and we couldn’t find any plausible answer. Of course, there are different characters in Arabic such as the comma (Arabic comma: “،”), but the asterisk is pretty much an asterisk everywhere and we wondered why it is a different character code.
In the following example we wrote a very simple website as an example to check if the position of the asterisks is always on the wrong side (seen from the Arabic point of view).

At the beginning it is important to set the “charset” to Unicode or you’ll just get question marks as output. As you can see, we set in the head tag the direction of the text alignment to “rtl”- this means “from right to left”- so that the output on the website would appear from right to left. This also applies to the input field in line 13. As you may notice, there’s an exclamation mark added in Latin that’s why it’s shown at the beginning of the Arabic word because it’s technically the last position in Latin. The following picture shows how it appears in the browser.
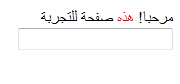
We decided to write the text in different HTML elements (here: div and span elements) to see if it makes a difference or not if the tested text is over multiple elements. As it turned out, it has no affect if the text is over multiple elements or not and it will be output in the right order, but the problem that the position of the asterisk is wrong to the eyes of an Arab still remains, which may cause great confusion.
Parameters in Western encoding preferred
There’s also a small disadvantage for Arabic developers. Parameter names cannot be put in Arabic. Because our tool only accepts characters “A”-“Z”, “a”-“z”, “0”-“9” and “_” for parameter names. That goes for test case names, as well. If you export your test cases with the Script Developer and you change the parameter names to Arabic in Eclipse, your test will fail unless you change the parameters in the data files as well, and then it will work just fine. The Script Developer will also show the modified Arabic parameter names and it will replay without any trouble. But if you check the parameter names in the Script Developer, you’ll notice that the name field is empty.
Programming in Arabic
Unfortunately, Arabic isn’t really supported in Eclipse on Windows, even if you run Eclipse in an Arabic version because it’s just a translated version of the platform and the operating system’s encoding is set to ISO Latin-1, i.e. any output in the console that is non-Latin will only be displayed as question marks. But in Linux it works because it supports UTF-8.
We were surprised that the Arabic version could align the Arabic text to the (far) right where it actually should begin, which is not supported by the Latin version of Eclipse. So, if you’re planning on developing a non-Latin website in Eclipse and you stumble upon a version of Eclipse in your language and decide to give it a try don’t get your hopes up because these versions are just translated, and might even be incomplete.
To sum up, we expanded our horizon by proving that our tool could also do test automation problem-free on non-Latin websites.