Most of you probably know the term Concurrent User. In the context of load and performance testing, this metric is often claimed the measure of all things, accompanied by the mentioning of astronomically high numbers we can’t really verify and that sometimes are simply used as sales argument for overpriced software products.
Today’s article is meant to shed some light on the concurrent user metric and the misunderstandings and myths surrounding it. Since Xceptance focuses on the internet and e-commerce, illustrations and examples will mainly refer to webshops; keep in mind, though, that the topic isn’t restricted to the domain of e-commerce load testing. Feel free to comment below, whether affirmative or critical.
Let’s start with a couple of key terms to help you understand what we’re talking about:
- Visit: In general, a visit occurs when you send a request to a server and, as a response, the website you requested is displayed. Has a duration starting with the first page view and ends with the last. Consists of one or more page views.
- Session: Technical term for a visit, basically the technical picture underlying it. Visit and session are often used synonymously.
- Page view or page impression: A single complete page delivered due to a request of an URL; in a world of Ajax, intermediate logical pages can be considered an impression or view. Can lead to further technical requests (HTML, CSS, Javascript, images etc.)
- Request: Submission of a request to a server, in the case of web applications mostly via HTTP/HTTPS protocols. Requested content may be HTML, CSS, Javascript as well as images, videos, Flash, or Silverlight applications – HTTP can deliver almost everything.
- Think time: Time period between two page views of a visit.
- Scenario: The course of a visit in terms of a use case (for example, to search something, to order something, or both). Representation of test cases meant to be run as load tests.
- Concurrent User: We don’t exactly know about them yet…
Load and Performance Test
A load test wants to reflect present load conditions or anticipated load conditions. In either case, it’s impossible for a load test to cover all eventualities and be economical at the same time. There’s a myriad of ways you can go to explore a webshop. Thus, you decide on the most typical ones at first and make a scenario out of them afterwards. Most of the time, we consider a scenario an isolated visit repeating the steps of the test case and thus using defined data (note that also random data is defined data).
Let’s assume three scenarios: a visitor that is just looking (Browsing), a visitor that puts products into the cart (Add2Cart), and a visitor that checks out as a guest and wants their ordered items to be shipped to an address (Order).
The users have to go through the following steps to completely cover the scenario:
Browsing user
- Homepage
- Select a catalogue
- Select a subcatalogue
- Select a product
Add2Cart user
- Browsing 1.-4.
- Put a product into the cart
Order user
- Add2Cart 1.-2.
- Proceed to checkout
- Enter an address
- Select a payment method
- Select a delivery type
- Place the order
The first challenge is choosing the content for the single actions, that is should we always go for the same product, the same catalogue, should the number of items or the size of the cart vary, etc. Only these three scenarios offer infinite possibilities of variation already. But let’s stick with the basic steps and the simple Browsing for now.
Concurrent Users
When testing against a server, the single running of Browsing would be a visit consisting of 4 page views and possibly further requests for static content. A second execution of the test with all data and connections (cookies, HTTP-keep-alive, and browser cache) having been reset would result in another visit. If you now run these two visits simultaneously and independently from one another, you end up with two concurrent users. Note that the notion “user” is actually not the exact right term as we’re talking about concurrent visits here. We prefer the term visit in this context and the person performing it is the visitor.
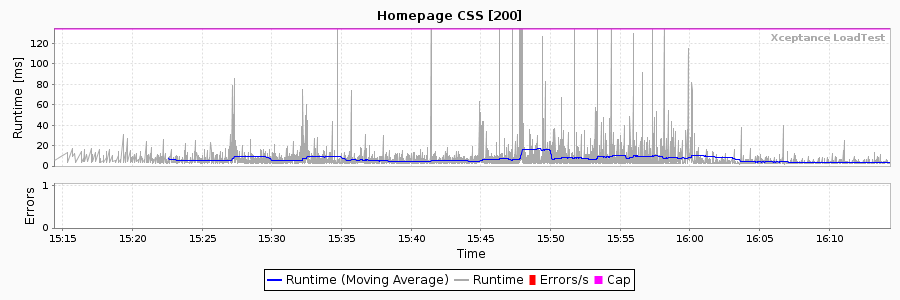
Both of our visitors execute 4 page views each, thus resulting in a total of 8 page views. As each page view has a runtime on the server, let’s say 1 sec, one visit takes at least 4 sec. Therefore, if one user repeats their visits for one hour, he or she completes 3,600 seconds / (4 seconds per visit) = 900 visits / hour. Two concurrent visitors result in 1,800 visits in total leading to an overall total of 1,800 visits x (4 page views per visit) = 7,200 page views.
We just said “if one user repeats”. Of course, a single user would never repeat a visit that many times. Just look at the user here as the load test execution engine repeating that independently of other “users”.
Think times
Now, the majority of users isn’t that fast, of course, which is why usually think times get included. The average think time currently amounts to something between 10-20 seconds, depending on the web presence. It used to be 40 seconds but today’s users are more experienced and user guidance has improved a lot so that they can navigate through a website much faster. Let’s assume a think time of 15 sec for our example.
A visit would now take (4 page views each takes 1 sec) + (3 think times each 15 sec). It’s only 3 think times because there’s none after the last click that terminates the visit. Accordingly, our visit duration is 49 sec. If we now have a visitor repeat that for an hour, we’ll end up with a user completing 3,600 sec / (49 sec per visit) = 73.5 visits per hour.
If we want to test 1,800 visits again, we need 1,800 visits / (73.5 visits per hour per user) = 24.5 users, about 25. The number of page views stays the same since 1 visit equals 4 page views and the number of visits is constant. These 25 users need to complete their visits simultaneously and in parallel but still independent of one another.
Any Number of Concurrent Users is Possible
We now have 25 concurrent users that produce the exact same traffic simulation as 2 users without a think time. The exact same traffic? No, of course not – this is where extreme parallelism and the unpredictability of both testing and reality comes into play.
If the requirement was the simulation of 1,800 visits per hour and 7,200 page views per hour, we could now randomly pick a think time and by doing so, determine any number of concurrent visits aka users between 2 and x. With respect to our simulation period of 1 hour, we get a new session (begin of a visit) every two seconds on the server side – 3,600 sec / 1,800 visits as our visits are equally distributed.
You can also question the numbers by approaching the problem from another perspective: if 100 users are simultaneously active, then they can simultaneously request 100 page views. In the worst case (note that 1 page view takes 1 sec on the server side), however, this would amount to 100 * 3,600 sec = 36,000 page views per hour. Since the requirement of 100 concurrent users is actually never bound to a certain period, you therefore have to assume that these users could potentially click at any time.
From this point of view, you’ll soon realize that the number of concurrent users can basically mean anything: much traffic, little traffic, little load, much load. Only by knowing the test cases and additional numbers such as visits and page views per time unit can you a) define a number of concurrent users and b) check each number by means of calculation against the other numbers.
Oh, and needless to say that 42 is always a good number of concurrent users… ;-)
Why 100,000 Concurrent Users Aren’t 100,000 Visits
What we want to emphasize here is that a temporal dimension is absolutely necessary. The requirement of 300,000 users would always imply they could click simultaneously which would produce 300,000 visits at one blow. Now, you may want to argue that they aren’t coming simultaneously. However, if the users aren’t simultaneously active aka started a visit, they aren’t concurrent users anymore and then you don’t need to simulate them in the first place.
Provided an equal distribution and an average visit duration of 49 sec, 300,000 users per hour that are often identified with visits (business-wise) in most cases, would result in the following: a user completes 3,600 / 49 sec visit duration = 73.5 visits per hour so that you end up with 300,000 / 73.5 = 4,081 concurrent visits aka real concurrent users at any given second. 4,081 concurrent visits produce 4 page views in 49 sec (visit duration) each, that is in 49 sec we have 16,324 page views, thus 333 page views per sec (see next paragraph).
In terms of page views without think times this means: 300,000 users are 1,200,000 page views (for our example above). Thus, you need to complete 1,200,000 page views / 3,600 seconds = 333 page views per second. Without any think time you would therefore need 333 users for the simulation.
Regarding the final result, the simulation of 4,081 users and 15 sec think time therefore equals the simulation of 333 users without think time. On the server side, both will result in the identical number of visits per time period, the identical number of page views, etc.
That’s impossible…
You may raise some objections to this and they are actually valid since, in reality, the think time would never be exactly 15 sec and the response time would never always be 1 sec. This is where coincidence comes into play. With respect to our example, let’s assume the think time to vary between 10 and 20 sec. The arithmetic mean would still be 15 sec.
What happens now results in the following calculation: In the worst case, the duration of all visits is only 4 sec + 3 * 10 sec = 34 sec. With 34 sec, our server now has to deliver as many visits and page views as it delivered within 49 sec before. Thus, our test wouldn’t cover 300,000 users with 4,081 concurrent test users but 3,600 / 34 * 4,081 = 432.105 visits per hour.
That means you need to define target numbers you want to support, or measure what the server is currently able to deliver. As soon as you say you have a number of x visits that could vary in their duration, you end up with a higher maximum number of visits you need to support but that you actually don’t want to test.
Note that our sole focus is set on the load and performance test here. You want to know if you can cope with the traffic x where you assume x to be a constant worst case that applies to a longer period of time. If you want to measure the server side beyond the maximum “good” case, you don’t aim at the performance anymore but at the overload behavior. Then you focus on stability and a predictable way of “decline”. All tests that are normally run at first, which is absolutely correct, are tests that want to identify or verify the good case.
But still…
Of course, it can make sense to test 4,081 users instead of 333 although there’s the same number of visits and page views per time period on the server side. 4,081 users can be concurrent users for a very short time and claim, for example, 4,081 webserver threads or sockets, while 333 users will never reach this number. Even if you keep the think time for 4,081 users at a constant level, the traffic wouldn’t be as synchronous as you planned it to be in the beginning.
In the worst case, you can’t test at all now because each test run leads to a different result. With the restriction to 333 users with none or just minimal think time, you restrict the “movement” of the system at first to measure it. If the system delivers what it should, the test may expand in its width aka both the think times and the number of concurrent users go up.
Steady Load Vs. Constant Arrival Rate
To resolve this dilemma a) without having to consider the server side while b) still being able to measure accurately, you can choose between two typical load profiles:
- Steady Load: Runs a fixed number of users that wait for the server, for instance, when it has long response times. This way you can’t reach the desired number of visits because users depend on the server’s response behavior. The profile is suitable for controlled measurements.
- Constant Arrival Rate: Users arrive as new visitors regardless of what is happening on the server side. When the server is too slow, new users will still try to come in. If the server can handle the load, the system runs stable and you just need your user number x (according to our calculation, 4,081, for example). If there are problems on the server side, then the user number automatically increases to x + n (for example, to a total of 10,000 users). In the ideal case, that means you only need 4,081 users but when the server behaves unexpectedly, up to 10,000 users will be activated. This way you can also test the overload behavior at the same time.
Finally…
We hope you were able to follow and that the mess of numbers didn’t get too bad. At times, the concurrent user topic is getting downright absurd… Feel free to comment, any remark is appreciated.
 We continue to share cool things with the community of software testers and developers. Today we are announcing the availability of our no coding test suite for XLT under the Apache License v2.0.
We continue to share cool things with the community of software testers and developers. Today we are announcing the availability of our no coding test suite for XLT under the Apache License v2.0.